Python实现提醒iOS描述文件有效期 背景 公司企业APP描述文件过期,没有提醒,导致当天出现不可用的问题。
为了避免再发生类似的问题,笔者想要写一个Python脚本,读取描述文件,获取有效期,设置提醒,且自动运行。
实现 首先再来理一下思路,所有的描述文件都在~/Library/MobileDevice/Provisioning Profiles/目录下,但是里面的内容通常不会自动删除,过期的或者重复的都在这个目录中,而且这个目录下的文件名是uuid命名的和Xcode中的文件名字也不能直接对应,所以一眼看去,只能用一个字形容:乱。
如果账号是管理员,直接登录在电脑上,项目中用的自动管理描述文件的,还好一些,现在会自动续期。但是如果账号是开发者,发布的描述文件没有权限用自动管理的,就需要注意这个描述文件有效期的问题。
再来理一下思路,想要的是一个读取描述文件夹下所有描述文件,获取描述文件中的内容,根据有效期,设置提醒,且自动运行的脚本。
那这里面最重要的是什么?是获取描述文件的内容,这关系到这个思路是否可行。
获取描述文件的内容 首先,来看下,描述文件的格式是uuid.mobileprovision,而这个.mobileprovision格式默认是直接安装到 Xcode 的,通过预览可以看到里面的内容。但是用脚本如何读取里面的内容呢?
首先用VSCode打开一个这样的描述文件,提示如下:
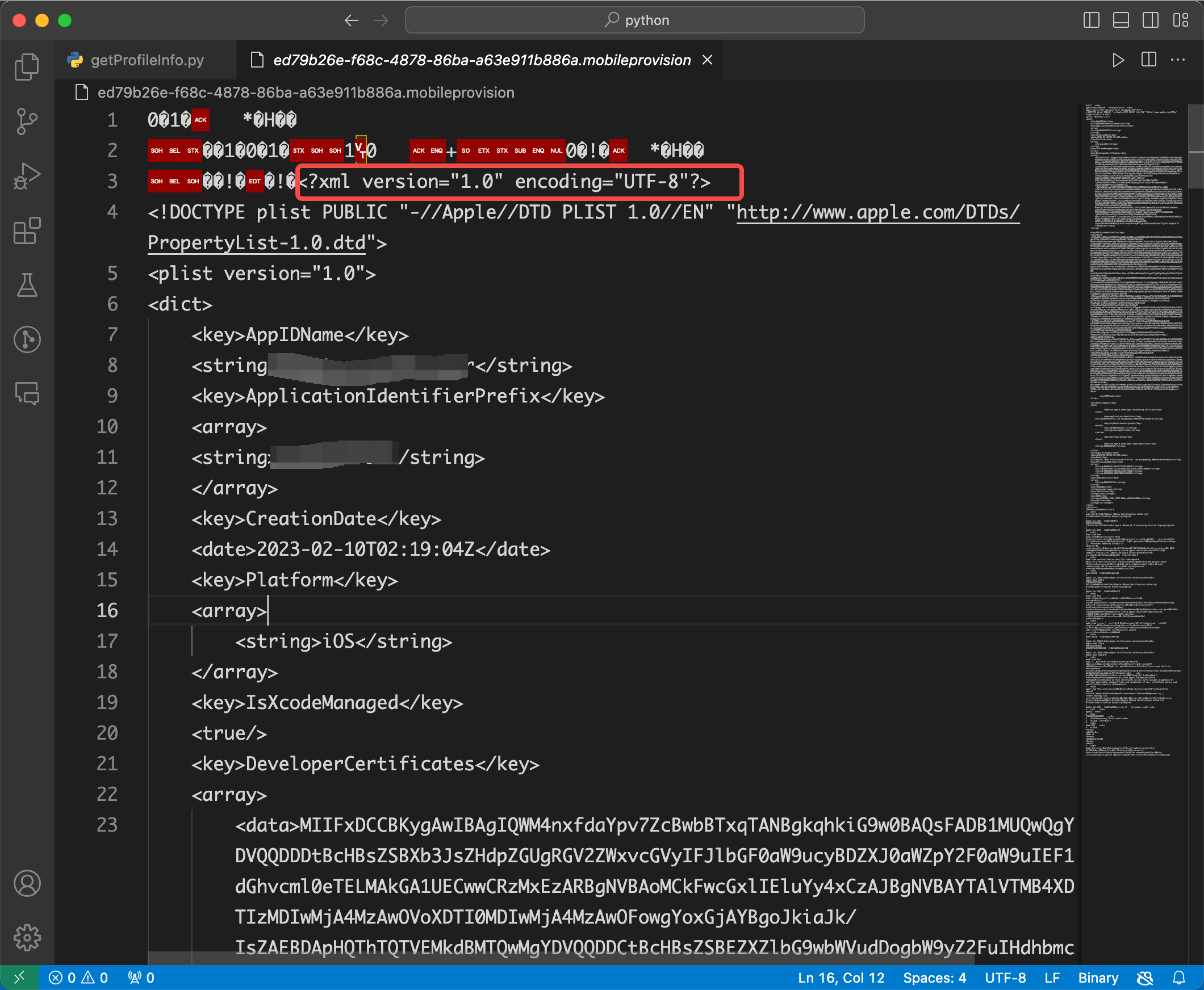
点击Open Anyway,然后选择用Text Editor的方式打开,可以看到,文件的开始和结束都是一堆乱码,中间却是一段plist格式的内容,如下:
所以猜想可以通过读取文件内容,截取开始和结束字符串,生成Plist文件。然后再通过读取 Plist 文件并解析获取对应的属性的内容。
下面来一步步尝试实现:
首先是读取文件内容,出师不利,在这一步就遇到了困难,设置encoding为utf-8,通过 open 读取到的文件内容一直为空,排查了好久。一开始以为是encoding指定的不对,调试后发现,设置errors='ignore'即可。
1 2 3 4 5 6 def readMobileProvisionContent (fileName ): fileFullName = fileName + ".mobileprovision" with open (fileFullName, "r" , encoding="utf-8" , errors="ignore" ) as file: fileContent = file.read() return fileContent
截取字符串,生成新的Plist格式的文件 获取到文件内容之后,下一步是截取指定字符串之间的内容,生成新的Plist格式的文件。根据上面的用文本格式查看.mobileprovision内容的分析,需要截取的内容是<?xml 和</plist>之间的内容,然后生成新的文件。这里需要注意的是,查找到结束位置时,获取到的Location,需要加上</plist>的长度才是完整的内容,详细代码如下:
Ps:这里走了一部分弯路,一开始转为XML格式的文件,生成后内容的读取并不方便,后来发现直接转为Plist格式的读取内容更为快捷。
1 2 3 4 5 6 7 8 9 def getSubContentBetween (startStr, endStr, sourceStr ): startLoc = sourceStr.find(startStr) if startLoc >= 0 : endLoc = sourceStr.find(endStr, startLoc) if endLoc >= 0 : endLoc += len (endStr) return sourceStr[startLoc:endLoc].strip()
接下来是用获取到的内容,生成Plist文件。在这里需要注意写入的方式,要用覆盖写入的方式,而不是拼接写入,防止多次执行出现问题。具体代码如下:
1 2 3 4 5 6 7 8 9 def generatePlistFile (fileName, fileContent ): fileFullName = fileName + '.plist' file = open (fileFullName, mode='w' , encoding='utf-8' ) for i in range (len (fileContent)): text = fileContent[i] file.write(text) file.close()
生成 Plist 文件后,接下来是解析 Plist 文件内容,获取到描述文件名字、有效期、UUID 等信息,下面具体来看看:
解析 Plist 文件 在解析Plist之前,需要思考一下,具体需要获取哪些字段,最终目的是提醒,所以过期日期字段是一定要解析的。然后需要考虑提醒的问题,是添加日历提醒,还是通过生成一个Excel 或者 html 的表格文件,用不同颜色区分不同有效期。这里用第二种生成 Excel 或者 html 的方式。
接下来需要考虑的就是显示哪些字段:
由于描述文件的名字中显示的是 UUID.mobileprovision,和 Xcode 中配置的不同,Xcode 中显示的是名字,所以名字和UUID都要显示出来,用于一一对应。
然后是描述文件对应的bundleID,用于确认具体的APP。
再然后是有效期相关信信息,CreationDate和ExpirationDate,以及计算出来的剩余天数。
Name
UUID
bundleID
CreationDate
ExpirationDate
剩余过期天数
单元格
单元格
单元格
单元格
单元格
单元格
解析Plist使用Python的plistlib库,日期计算使用datetime库,都不需要额外安装,直接导入使用,具体代码如下:
Ps:
解析出来的CreationDate和ExpirationDate都是 date 类型,而不是 string 类型。
open file的 mode 需要指定为rb,如果指定为r,则会提示TypeError: startswith first arg must be str or a tuple of str, not bytes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import plistlib import datetime def parsePlistInfo (fileName ): fileFullName = fileName + ".plist" with open (fileFullName, mode='rb' ) as plist: plistDic = plistlib.load(plist) name = plistDic["Name" ] uuid = plistDic["UUID" ] creationDate = plistDic["CreationDate" ] expirationDate = plistDic["ExpirationDate" ] entitlements = plistDic["Entitlements" ] applicationIdentifier = entitlements["application-identifier" ] teamIdentifier = entitlements["com.apple.developer.team-identifier" ] bundleIDLoc = applicationIdentifier.find(teamIdentifier) + len (teamIdentifier) + 1 bundleID = applicationIdentifier[bundleIDLoc:].strip() currentDate = datetime.datetime.now() dateDelta = expirationDate - currentDate leftDays = dateDelta.days dateformatterStr = "%Y %m %d %H:%M:%S" creationDateStr = creationDate.strftime(dateformatterStr) expirationDateStr = expirationDate.strftime(dateformatterStr) return (name, uuid, bundleID, creationDateStr, expirationDateStr, leftDays)
到这一步说明之前的思路是可行的,即读取描述文件xxx.mobileprovision的内容,生成新的plist格式的文件,然后再通过读取plist的content获取对应属性的值,并计算到期日期。
最后需要考虑的是设置提醒的逻辑,起初打算直接写入 Mac 日历,调研后发现能做到的是生成日历格式的文件,然后手动导入。所以改为生成一个 html或Excel 文件,对快过期和已过期的标红显示,然后自动发送到邮箱(在这里实现为直接打开)。下面来看一下生成html或Excel的逻辑。
生成 html或Excel 文件 在生成之前需要考虑哪些状态是需要标红显示的:如果剩余天数小于 0,说明已过期;如果剩余天数小于 30,说明一个月内过期,这两种可以高亮显示;如果大于 30,则说明有效期大于 1 个月,只需要正常显示即可。
生成html文件 先来看下生成 html 的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def writeToHtml (infoTurple, filepath ): htmlPath = filepath + "iOS描述文件统计.html" columnTitles = ['name' , 'uuid' , 'bundleID' , '创建日期' , '过期日期' , '有效期' ] fileout = open (htmlPath, 'w' ) table = "<table border='1' width='70%'>\n" table += " <tr>\n" for title in columnTitles: table += " <th>{0}</th>\n" .format (title.strip()) table += " </tr>\n" columnCount = len (infoTurple) table += " <tr>\n" for i, x in enumerate (infoTurple): if i == columnCount - 1 : color = '#FFFFFF' valueStr = str (x) + "天内过期" if x < 0 : valueStr = "已过期" color = '#FF0000' elif x < 30 : valueStr = str (x) + "天内过期" color = '#FFF000' else : valueStr = "还有" + str (x) + "天过期" table += " <td bgcolor='{bgcolor}'>{value}</td>\n" .format (bgcolor=color, value=valueStr) else : table += " <td>{0}</td>\n" .format (x) table += " </tr>\n" table += "</table>" fileout.writelines(table) fileout.close()
运行后显示效果,如下图所示:
生成Excel文件 再来看一下,如何生成 Excel 格式的文件,毕竟如果要发送给他人,Excel格式的比html的更正式点。
生成Excel格式的文件,需要安装三方库,这里使用的是openpyxl,首先用如下命令安装:
然后生成Excel的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from openpyxl import Workbookfrom openpyxl.styles import PatternFillfrom openpyxl.styles.colors import Colordef writeToExcel (infoTurple, filepath ): excelPath = filepath + "iOS描述文件统计.xlsx" wb = Workbook() ws = wb.active ws.title = '描述文件信息' columnTitles = ['name' , 'uuid' , 'bundleID' , '创建日期' , '过期日期' , '有效期' ] for i, x in enumerate (columnTitles): c1 = ws.cell(row = 1 , column = i + 1 ) c1.value = x count = len (infoTurple) for i, x in enumerate (infoTurple): columnIndex = i + 1 c2 = ws.cell(2 , column = columnIndex) if columnIndex == count: color = '00FFFFFF' if x < 0 : c2.value = "已过期" color = '00FF0000' elif x < 30 : color = '00FFF000' c2.value = str (x) + "天内过期" else : c2.value = "还有" + str (x) + "天过期" color = '00FFFFFF' c2.fill = PatternFill(patternType='solid' ,fgColor=color) else : c2.value = x wb.save(excelPath)
运行后效果如下:
自动打开最终生成的文件 最终生成的文件,可以通过脚本发送给相关人,或者直接打开以达到提醒的效果。这里用的是直接打开。具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 import platformimport subprocessdef openFile (fullFilePath ): systemType = platform.platform() if 'mac' in systemType: fullFilePath = fullFilePath.replace('\\' , '/' ) subprocess.call(["open" , fullFilePath]) else : fullFilePath = fullFilePath.replace("/" , "\\" ) os.startfile(fullFilePath)
整体处理 截止到这一步,针对单个描述文件的处理已经完成,即对单个描述文件,解析内容并生成可视化提醒的一整套逻辑都已经实现。下面需要考虑的是另外三个方面:
批量处理逻辑:熟悉 iOS 开发的都知道,描述文件是存放在打包机或者自己电脑上的~/Library/MobileDevice/Provisioning Profiles/中,里面存放了许多描述文件,所以下一步首先要考虑的是批量扫描处理的逻辑。
过期自动删除的逻辑:这个可以说是一个feature,因为~/Library/MobileDevice/Provisioning Profiles/这个目录下,如果没有清理过,可能存在很多已过期的文件,所以既然能获取到这个文件是否已过期,那么就能实现已过期的文件直接删除,但是这一步是可选,取决于自己是否需要。
重复文件自动标记的逻辑:因为描述文件所在的目录中可能会存在多个描述文件有同样的名字、同样的bundleID,都有效,但有效期不同的情况;这种情况可能会出现打包的时候不同版本用了不同的描述文件,从而导致 APP 不同版本有不同的有效期。所以针对这种情况,需要把名字重复的也添加高亮标记提醒,然后手动进行确认处理。
批量处理需要注意的是,由于描述文件所在目录~/Library/MobileDevice/Provisioning Profiles/是相对路径,需要转为绝对路径再打开。脚本所在目录就没有限制,不需要和描述文件放在同一个文件夹也可。
再来思考一下整体处理的思路:
打开描述文件所在文件夹
遍历读取每个描述文件
针对每个描述文件进行如下处理:
读取描述文件内容
截取开始和结束字符串,生成新的 Plist 文件,放入暂存文件夹中
读取 Plist 文件,获取指定字段的值
存储读取到的内容到指定数组
在写入过程中,存储之前每步写入的文件名;如果发现当前文件名在已写入的数组,说明是重复文件,则把当前文件名放入重复文件数组中。
根据剩余有效期,判断文件是否过期,存储已过期的文件UUID到过期数组
遍历数组将读取到的内容写入最终生成的文件
在写入过程中,判断剩余有效期,针对快过期和已过期的做标记显示
如果发现当前文件名在重复文件的数组中,则对当前文件名做标记显示
根据需要,遍历过期数组,删除每个过期的描述文件
删除暂存文件夹中生成的所有 Plist 文件
打开最终生成的Excel或html文件
整体处理的完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 import plistlibimport datetimeimport osfrom openpyxl import Workbookfrom openpyxl.styles import PatternFillfrom openpyxl.styles.colors import Colorimport shutilimport platformimport subprocessdef readMobileProvisionContent (fileName ): fileFullName = fileName + ".mobileprovision" with open (fileFullName, "r" , encoding="utf-8" , errors="ignore" ) as file: fileContent = file.read() return fileContent def getSubContentBetween (startStr, endStr, sourceStr ): startLoc = sourceStr.find(startStr) if startLoc >= 0 : endLoc = sourceStr.find(endStr, startLoc) if endLoc >= 0 : endLoc += len (endStr) return sourceStr[startLoc:endLoc].strip() def generatePlistFile (fileName, fileContent ): fileFullName = fileName + '.plist' file = open (fileFullName, mode='w' , encoding='utf-8' ) for i in range (len (fileContent)): text = fileContent[i] file.write(text) file.close() def parsePlistInfo (fileName ): fileFullName = fileName + ".plist" with open (fileFullName, mode='rb' ) as plist: plistDic = plistlib.load(plist) name = plistDic["Name" ] uuid = plistDic["UUID" ] creationDate = plistDic["CreationDate" ] expirationDate = plistDic["ExpirationDate" ] entitlements = plistDic["Entitlements" ] applicationIdentifier = entitlements["application-identifier" ] teamIdentifier = entitlements["com.apple.developer.team-identifier" ] bundleIDLoc = applicationIdentifier.find(teamIdentifier) + len (teamIdentifier) + 1 bundleID = applicationIdentifier[bundleIDLoc:].strip() currentDate = datetime.datetime.now() dateDelta = expirationDate - currentDate leftDays = dateDelta.days dateformatterStr = "%Y-%m-%d %H:%M:%S" creationDateStr = creationDate.strftime(dateformatterStr) expirationDateStr = expirationDate.strftime(dateformatterStr) return (name, uuid, bundleID, creationDateStr, expirationDateStr, leftDays) def writeToHtml (infoTurpleList, repeatNameList, filepath ): htmlPath = filepath + "iOS描述文件统计.html" columnTitles = ['name' , 'uuid' , 'bundleID' , '创建日期' , '过期日期' , '有效期' ] fileout = open (htmlPath, 'w' ) table = "<table border='1' width='70%'>\n" table += " <tr>\n" for title in columnTitles: table += " <th>{0}</th>\n" .format (title.strip()) table += " </tr>\n" for row, infoTurple in enumerate (infoTurpleList): columnCount = len (infoTurple) table += " <tr>\n" for i, x in enumerate (infoTurple): color = '#FFFFFF' valueStr = x if i == 0 : if x in repeatNameList: color = '#FFF000' table += " <td bgcolor='{bgcolor}'>{value}</td>\n" .format (bgcolor=color, value=valueStr) elif i == columnCount - 1 : if x < 0 : valueStr = "已过期" color = '#FF0000' elif x < 30 : valueStr = str (x) + "天内过期" color = '#FFF000' else : valueStr = "还有" + str (x) + "天过期" table += " <td bgcolor='{bgcolor}'>{value}</td>\n" .format (bgcolor=color, value=valueStr) else : table += " <td>{0}</td>\n" .format (x) table += " </tr>\n" table += "</table>" fileout.writelines(table) fileout.close() def writeToExcel (infoTurpleList, repeatNameList, filepath ): excelPath = filepath + "iOS描述文件统计.xlsx" wb = Workbook() ws = wb.active ws.title = '描述文件信息' columnTitles = ['name' , 'uuid' , 'bundleID' , '创建日期' , '过期日期' , '有效期' ] for i, x in enumerate (columnTitles): c1 = ws.cell(row = 1 , column = i + 1 ) c1.value = x for row, infoTurple in enumerate (infoTurpleList): count = len (infoTurple) for i, x in enumerate (infoTurple): columnIndex = i + 1 cellColumn = ws.cell(row = row + 2 , column = columnIndex) if i == 0 : cellColumn.value = x if x in repeatNameList: cellColumn.fill = PatternFill(patternType='solid' ,fgColor='00FFF000' ) elif columnIndex == count: color = '00FFFFFF' if x < 0 : cellColumn.value = "已过期" color = '00FF0000' elif x < 30 : color = '00FFF000' cellColumn.value = str (x) + "天内过期" else : cellColumn.value = "还有" + str (x) + "天过期" color = '00FFFFFF' cellColumn.fill = PatternFill(patternType='solid' ,fgColor=color) else : cellColumn.value = x wb.save(excelPath) def createDir (fileDir ): if not os.path.exists(fileDir): os.mkdir(fileDir) def openFile (fullFilePath ): systemType = platform.platform() if 'mac' in systemType: fullFilePath = fullFilePath.replace('\\' , '/' ) subprocess.call(["open" , fullFilePath]) else : fullFilePath = fullFilePath.replace("/" , "\\" ) os.startfile(fullFilePath) def findAllMobileprovision (filePath ): resultList = [] for root, ds, fs in os.walk(filePath): targetFileExt = '.mobileprovision' for f in fs: if f.endswith(targetFileExt): fullProfilePath = os.path.join(root, f).replace(targetFileExt, '' ) resultList.append(fullProfilePath) return resultList def delExpiredMobileProvision (fileDir ): for idx, file in enumerate (fileDir): targetFullPath = file + '.mobileprovision' if os.path.exists(targetFullPath): os.remove(targetFullPath) print ("已删除: " + targetFullPath) else : print ('文件不存在: ' + targetFullPath) def main (): resultFilePath = '/Users/xxx/Desktop/TempProfilePath/' mobileProvisionPath = '/Users/xxx/Library/MobileDevice/Provisioning Profiles/' tempPlistDir = resultFilePath + 'Plist/' createDir(resultFilePath) createDir(tempPlistDir) mobileProfisionList = findAllMobileprovision(mobileProvisionPath) plistInfoList = [] expiredList = [] plistInfoNameList = [] repeatNameList = [] for idx, fileName in enumerate (mobileProfisionList): startTag = '<?xml ' endTag = '</plist>' contentStr = readMobileProvisionContent(fileName) plistContent = getSubContentBetween(startTag, endTag, contentStr) plistPath = fileName.replace(mobileProvisionPath, tempPlistDir) generatePlistFile(plistPath, plistContent) plistInfo = parsePlistInfo(plistPath) plistInfoList.append(plistInfo) plistName = plistInfo[0 ] if plistName in plistInfoNameList: repeatNameList.append(plistName) else : plistInfoNameList.append(plistName) if plistInfo[5 ] < 0 : expiredList.append(fileName) writeToHtml(plistInfoList, repeatNameList, resultFilePath) writeToExcel(plistInfoList, repeatNameList, resultFilePath) shutil.rmtree(tempPlistDir) openFile(resultFilePath + 'iOS描述文件统计.xlsx' ) openFile(resultFilePath + 'iOS描述文件统计.html' ) if __name__ == '__main__' : main()
自动运行 还差最后一步,设置脚本自动运行,参考mac 自动执行python项目 ,根据需求设置脚本每隔多久自动运行即可。
总结 再来回顾一下整体的处理逻辑,由于原有的描述文件分析查看不方便,所以想要通过脚本读取描述文件内容,生成一种便于阅读的格式,并用于提醒。
首先做的是针对单个描述文件验证,这种思路是否可行,通过读取文件、截取文件内容、生成新的便于处理格式,获取想要的信息,最终生成便于阅读的格式。
单个文件的处理通过验证,发现可行后,再来做针对整个描述文件夹的处理:通过扫描文件夹,然后针对文件夹中的每个文件都做如上处理,并添加过期和重复的处理逻辑,把最终的信息拼接到一起,即是对所有文件的处理逻辑。
最后再通过设置定时运行,来达到提醒的目的,还可以通过发送邮件,定时提醒相关人员,感兴趣的可以自己实现。
整体的流程大致如上,流程不太复杂,但处理稍微有点绕,网上并没有类似的处理方案,所以这里记录分享出来,供大家参考。
参考