iOS CreateML的使用
CreateML使用
背景
业务需求,想要通过拍照识别照片中指定物体的数量或者物体的种类。而这种物体的模型网上没有训练好的,需要从头开始。所以调研了苹果的createML的实现方案,具体操作如下:
需求是:通过拍照识别照片中指定物体的数量,实现方案大致有几种:
- 通过第三方平台,训练数据,生成模型,提供前端使用
- 自己搭建平台,训练数据,生成模型,提供前端使用
- 通过苹果的CreateML工具,训练数据,生成模型,供iOS使用或转换成其他模型使用
对比可以发现,通过苹果的CreateML工具,可以省去搭建平台的过程。下面来看看怎么使用CreateML。
使用CreateML的整体流程是:
- 有大量的样本
- 标注所有的样本
- 用这些样本训练生成模型
- 验证模型的识别率
- 测试模型效果
- 导出模型供使用
需求是通过拍照识别照片中指定物体的数量,所以对我来说样本就是照片,下面就来看下怎么生成CreateML训练需求的标注信息。
使用
样本照片标注
首先要有大量的样本照片,这里由于是调研测试,所以选取20张照片,照片来源是百度图片。。。麻烦的是照片标注,由于苹果CreateML训练需要指定格式的JSON文件,格式如下:
1 |
|
所以找一个能直接导出Create ML支持的JSON格式的标注工具尤其重要。这里参考Object Detection with Create ML: images and dataset使用roboflow来进行标注,具体使用如下:
roboflow登陆后,会有引导步骤,建立workSpace,workSpace下新建项目,也可以邀请用户加入到同一个workSpace,界面如下:
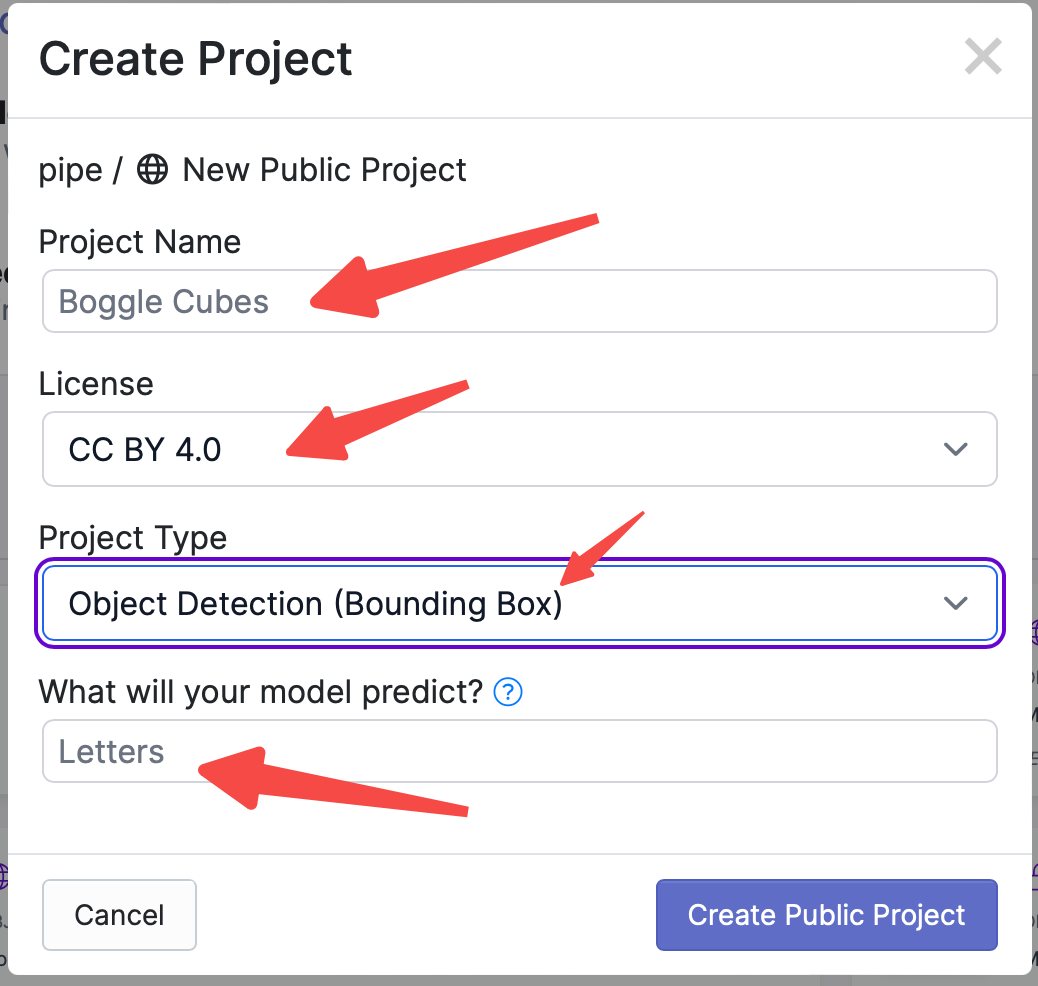
点击Create Project,需要输入项目的名字,选择项目的License,选择项目的功能,输入要标记的物体的名字,界面如下:
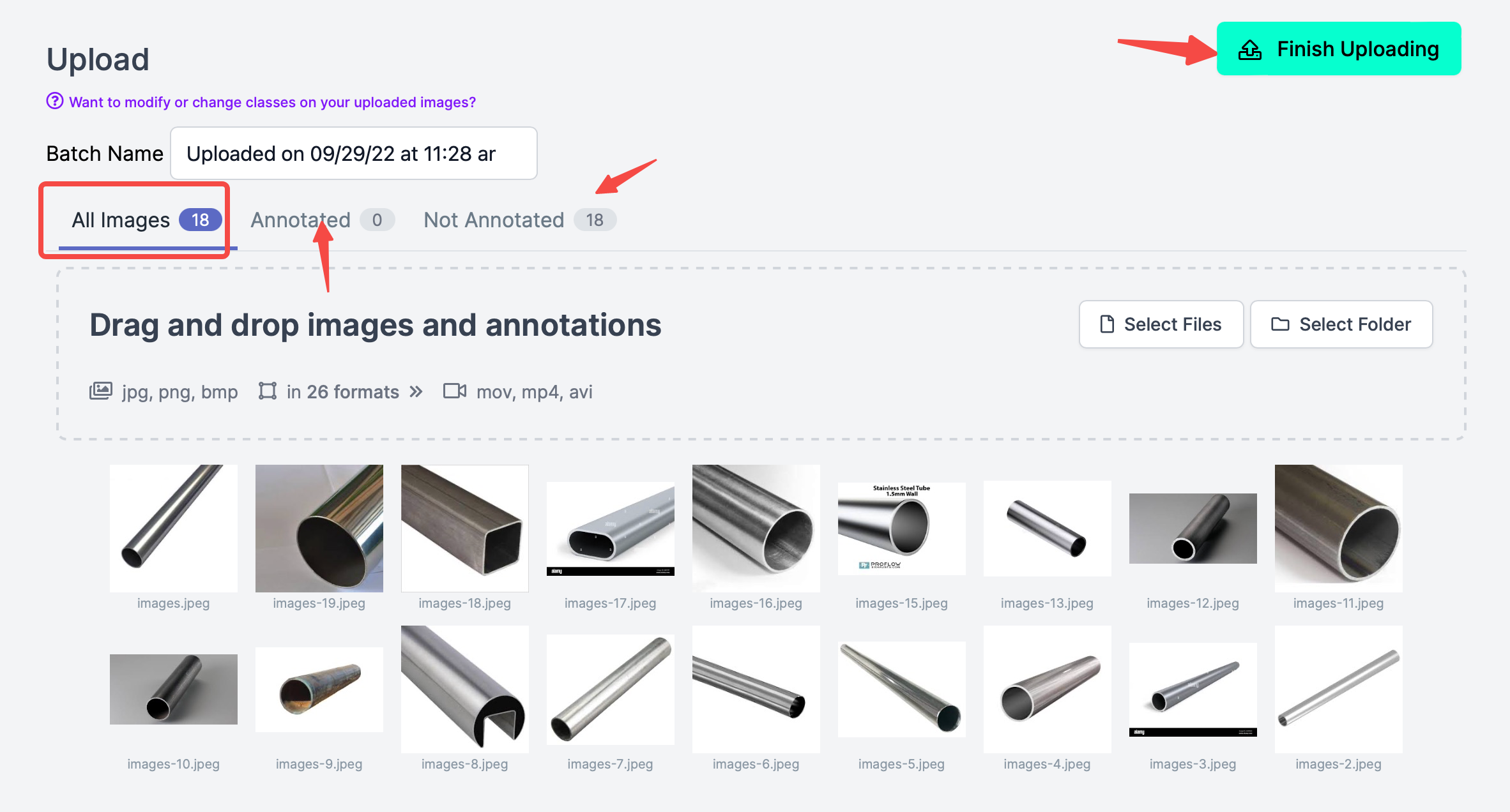
然后导入照片,比如去网上下载十几张钢管的照片,训练识别钢管(通常应该是很多很多照片,样本越多,训练出的模型就越准确这里只用于演示流程,所以选取的照片不多);注意照片上传完成后,不要点击右上角的Finish Uploading,因为此时还没有标注,注意All Images(18),Annotated(0),说明没有一张标注的。
双击任意一张照片,即可进入标注页面,
- 在标注页面,要先选择最右侧标注工具,默认是长方形框框标注;
- 然后选择标注的范围,注意的是使用曲线标注时,起始和结束的两个点要闭合;
- 然后在弹出的Annotation Editor框中,输入要标记的label,然后点击保存;
- 如果有多个标记,则重复上面的过程;
- 所有标记都完成后,点击左侧的返回即可;
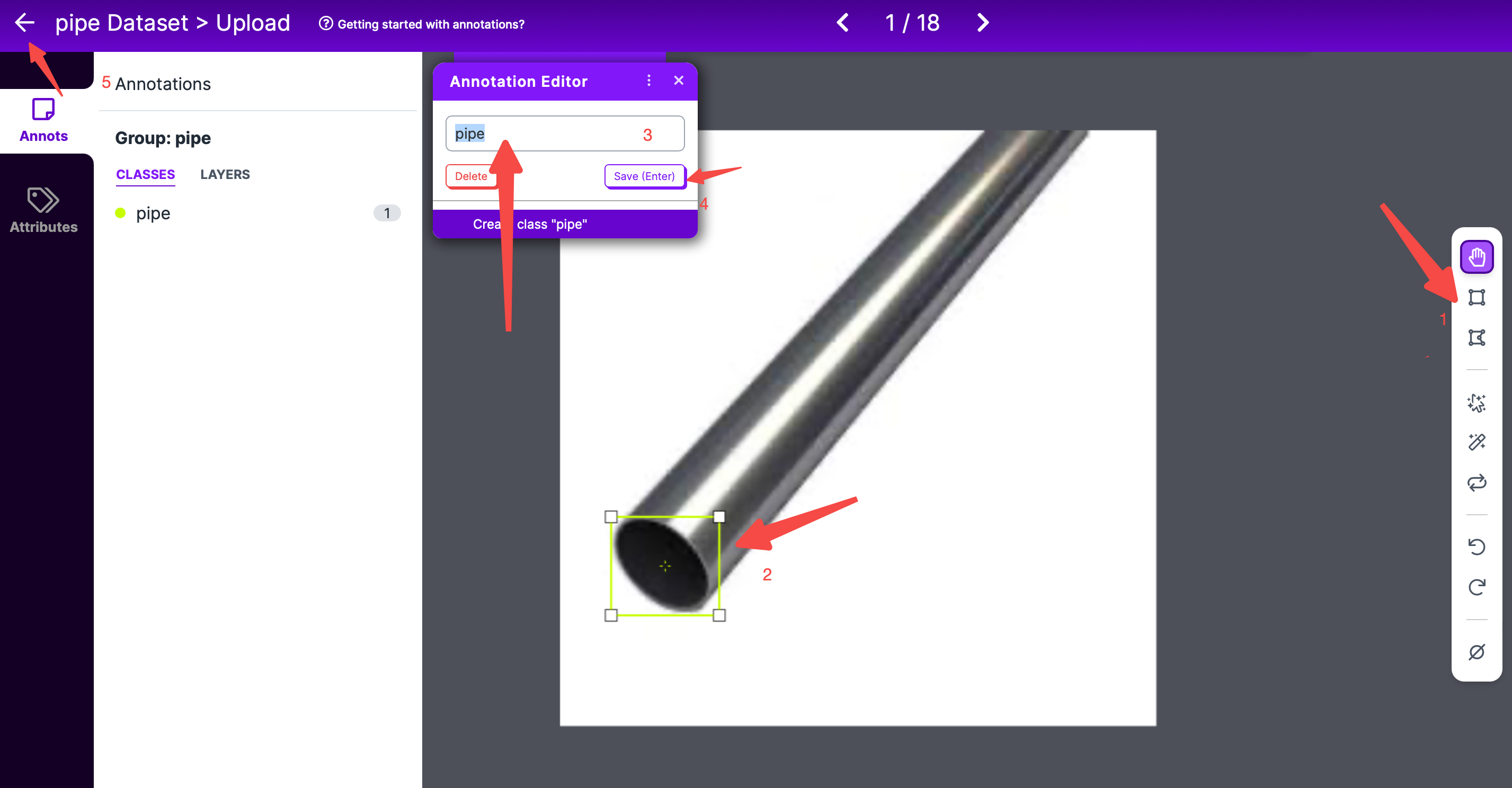
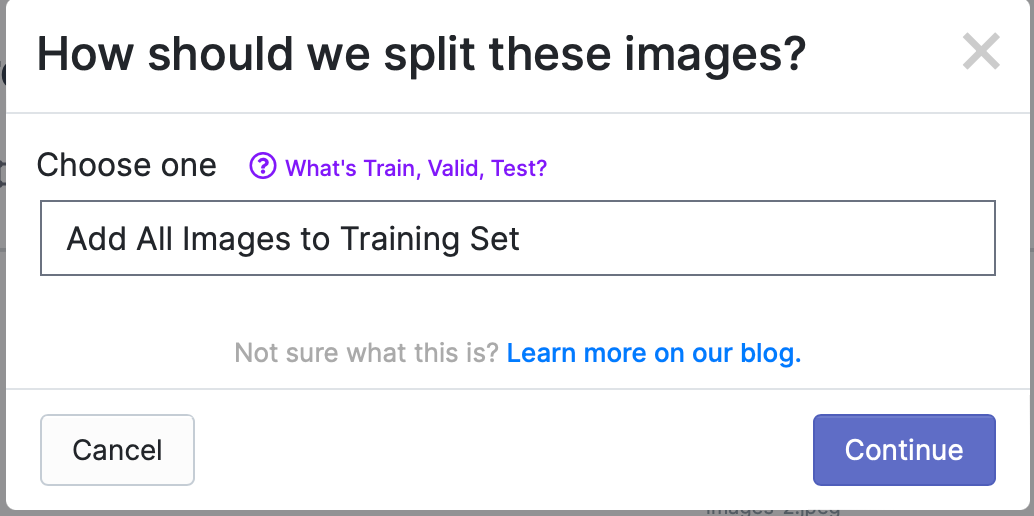
所有照片都标记好之后,点击Finish Uploading,会弹出如下提示框,选择如何分配照片给Train、Valid和Test,默认是所有照片都用于Train,如下:
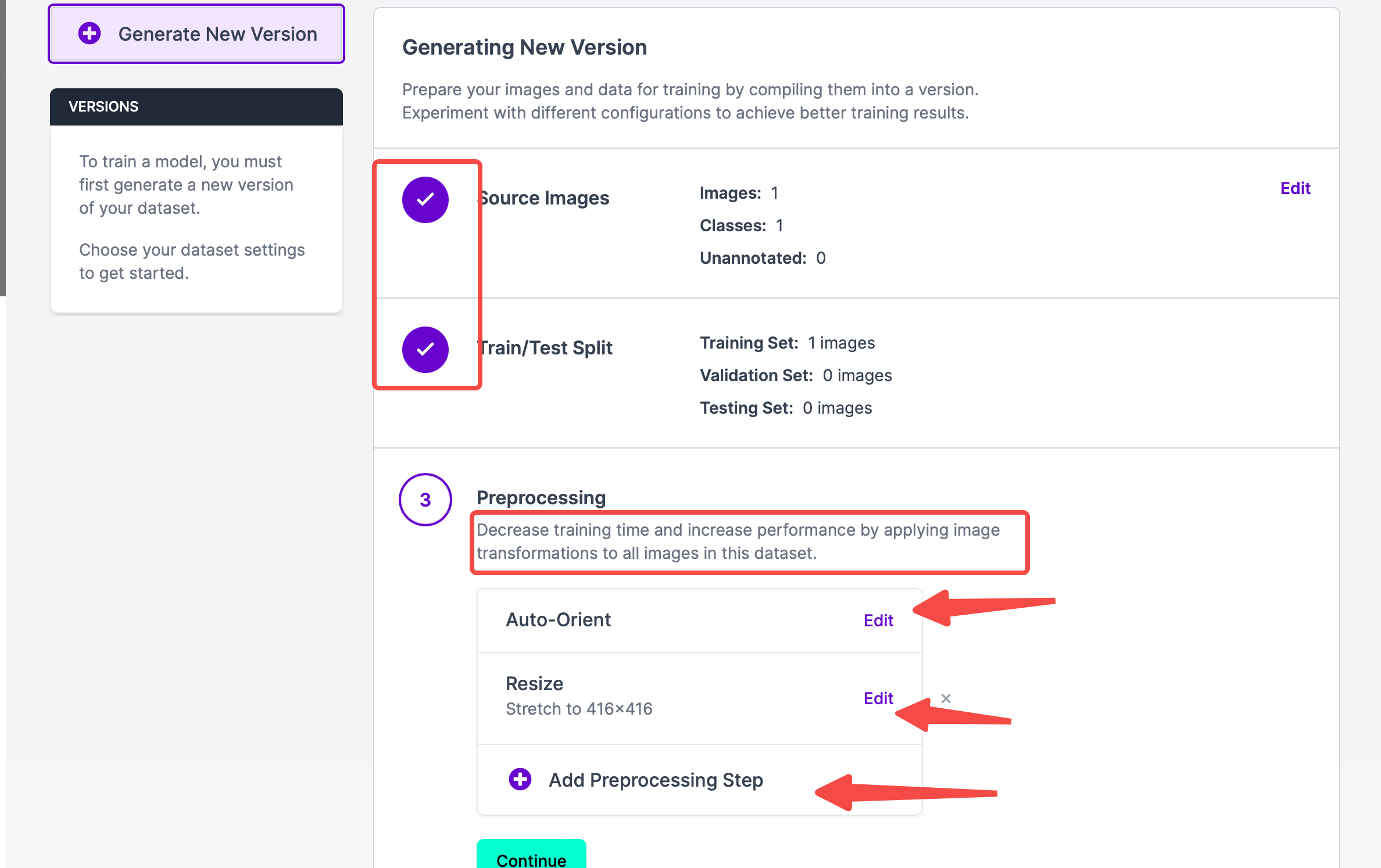
点击Continue,进入下一步。可以看到步骤1和2都已完成,如果想要编辑上面两个步骤,也可以移动鼠标到对应模块的右半边,会出现编辑按钮;目前所在步骤3,Auto-Orient意思是Discard EXIF rotations and standardize pixel ordering.,如果不需要可以删除这步;Resize是把照片重新调整大小。也可以添加Preprosession Step。这个步骤的预处理的目的是用于节省最终训练时间。
点击Continue,进入步骤4,这个步骤的目的是通过生成训练集中每个图像的增强版本,为模型创建新的训练示例以进行学习。如果不需要,可以直接点击Continue,进入下一步。
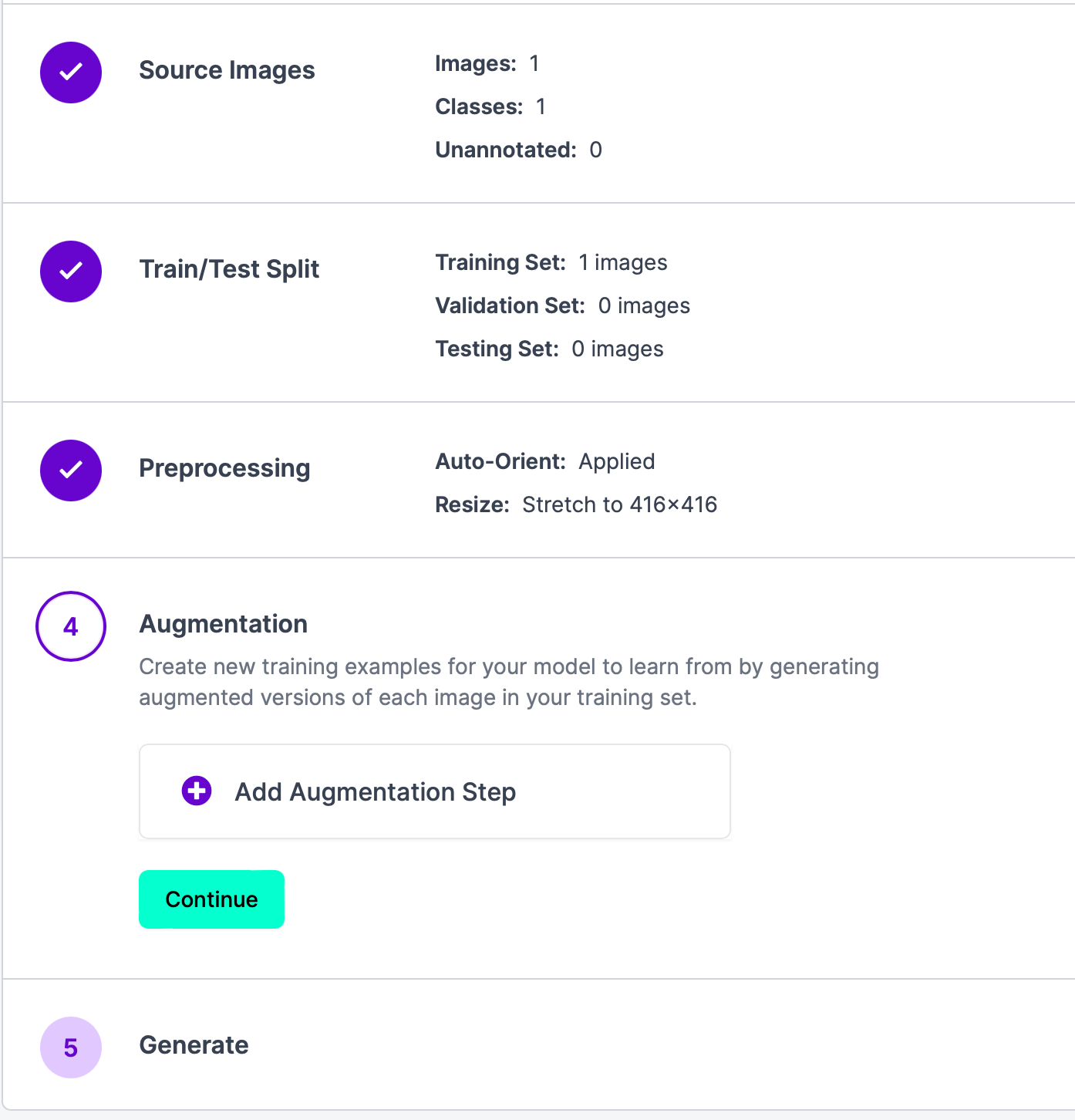
最后一步,就是生成结果,点击Generate,然后等待结果出现。结果如下:
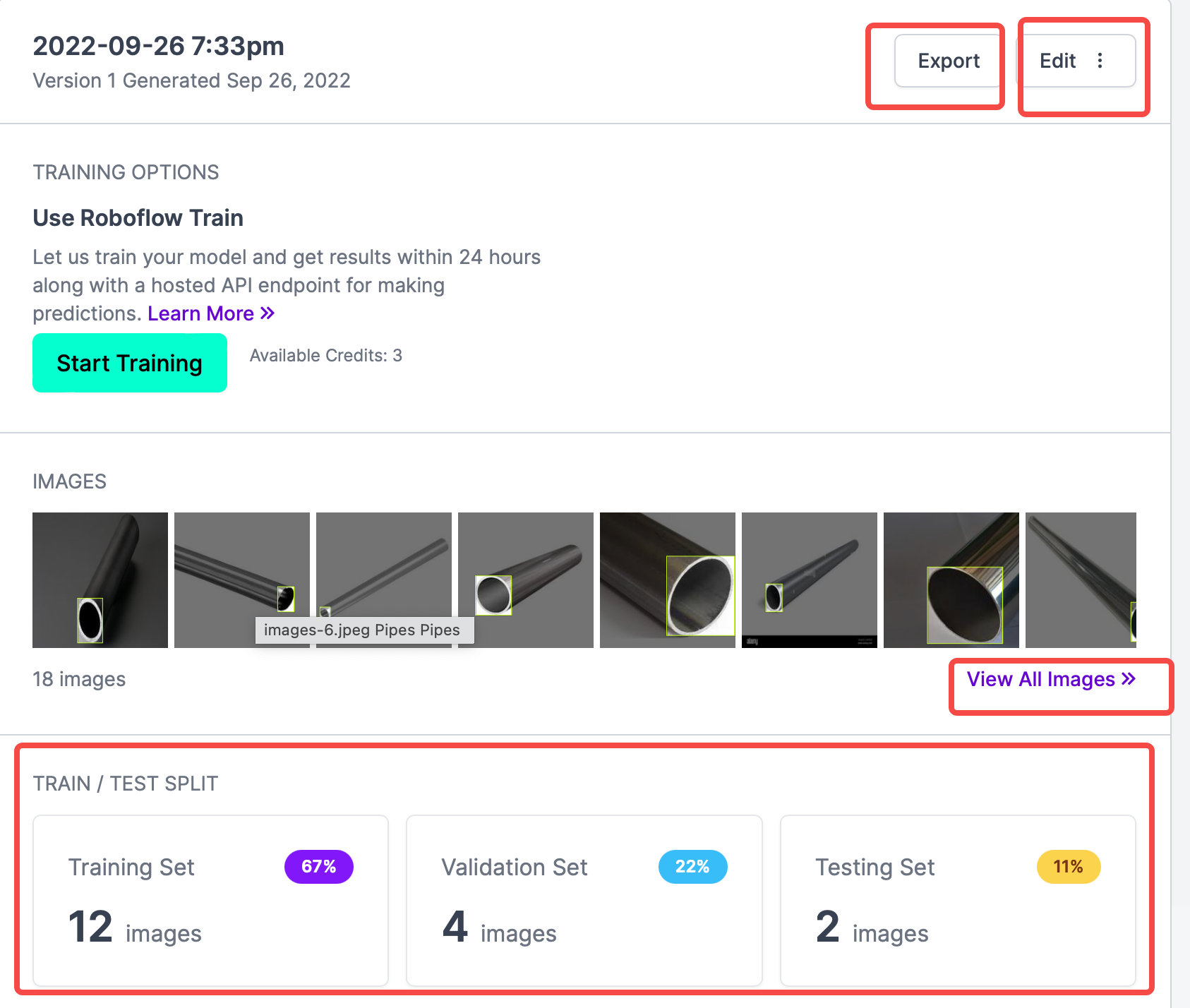
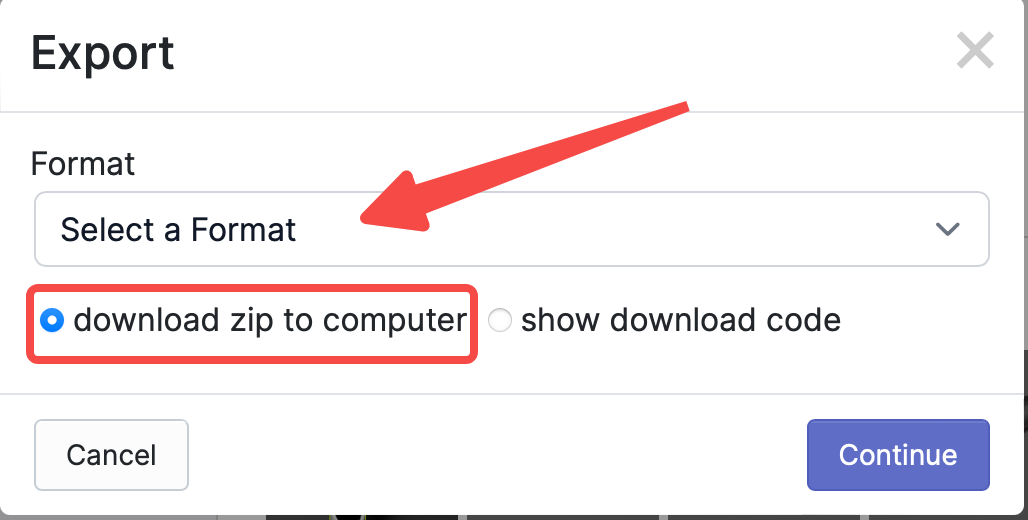
从上图可以看到,所有标注的照片、Train和Validation和Test的数量,Start Training按钮是网站提供的在线训练功能,这里用不到;需要的是导出CreateML类型的标注信息,所以点击Export,在弹出的弹窗中选择要导出的格式,这个网站最好用的就是导出支持的格式很多,这里选择CreateML,然后选中download zip to computer,点击Continue。
)
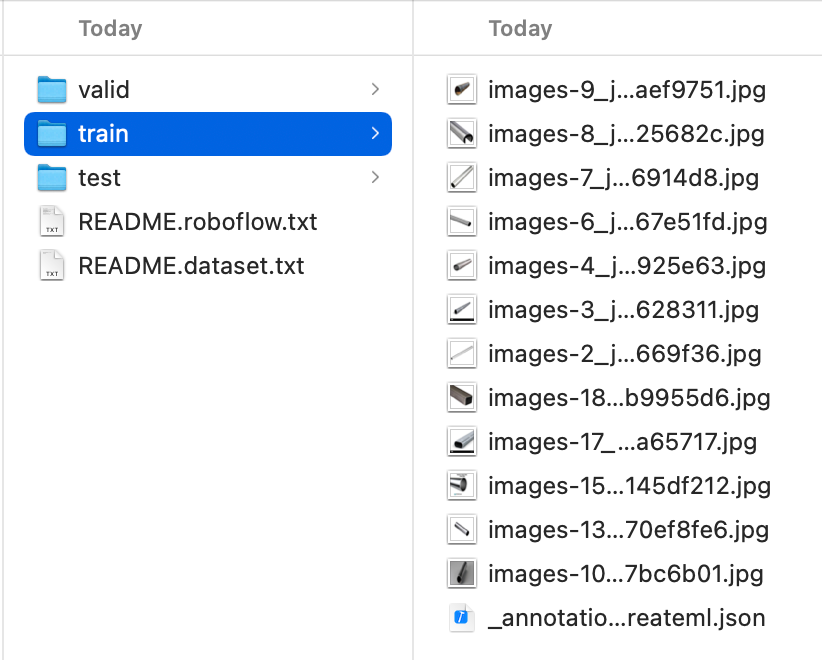
在finder中找到下载的xxx.createml.zip,解压,查看文件夹,内容如下,可以看到Train、Valid、Test都已分类好,查看Train文件夹下_annotations.createml.json,可以看到格式和CreateML需要的一致,可以直接使用。
CreateML使用
选择Xcode -> Open Developer Tool -> Create ML,打开CreateML工具,如下:
然后进入选择项目界面,如果已有CreateML项目,则选择打开;没有则选择要保存的文件夹,然后点击左下角的New Document进入创建页面,创建页面如下:
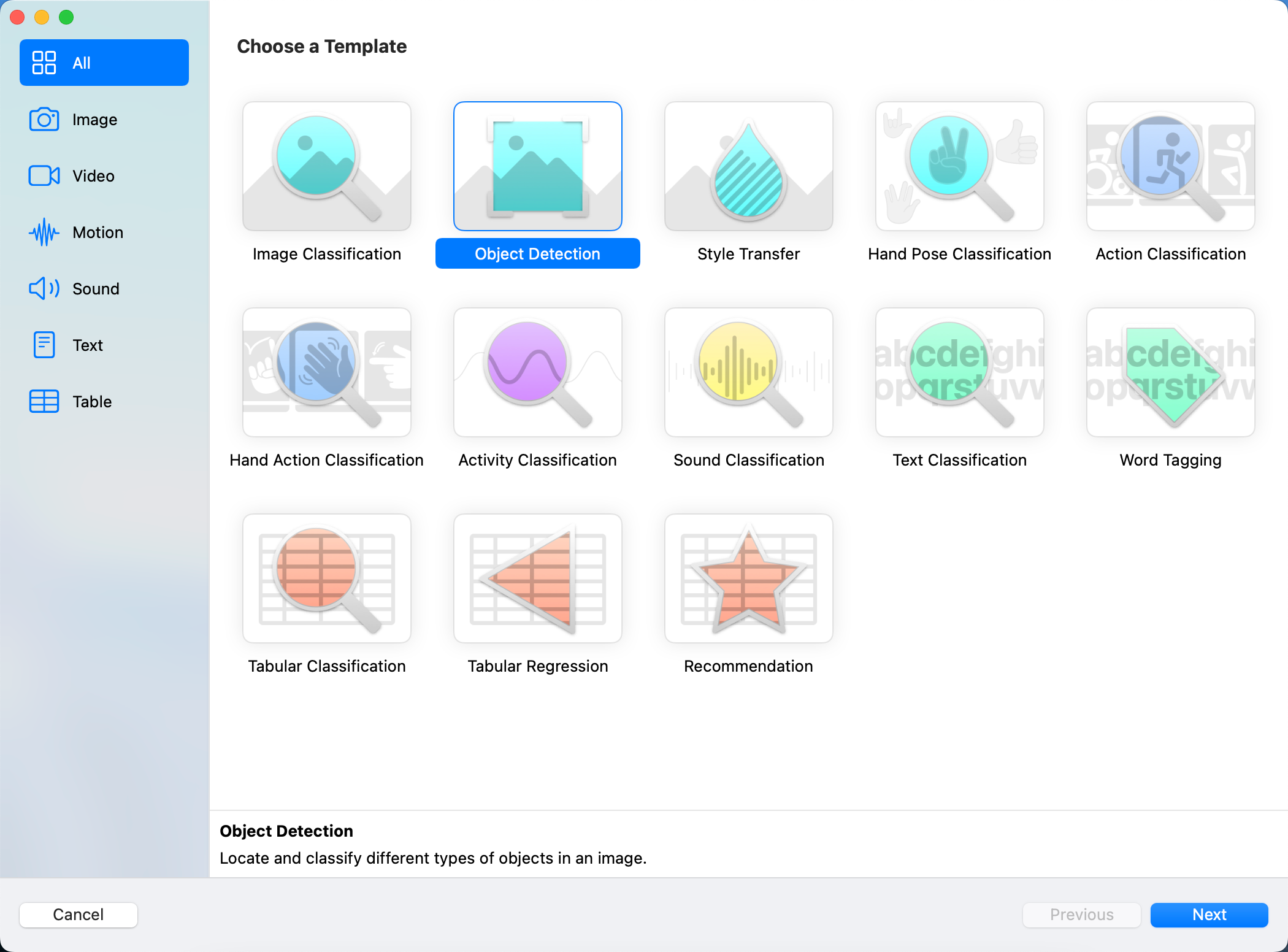
根据需要,选择要创建的模板,这里选择Object Detection,然后输入项目名字和描述,如下:
这里歪个楼,看到
Text Classification和Word Tagging,想起来商店里的短信过滤APP,可能就是用大量的垃圾短信,然后通过CreateML训练出模型,再导入到项目中,在项目中继续用Core ML来不断更新这个模型,从而针对每个人做到识别效果更好。
点击下一步,进入主界面,如下图所示,可以看到有以下几部分:
- 上方中间的
Setting、Traning、Evaluation、Preview、Output代表CreateML的几个步骤,可以切换查看,目前后面个步骤都是空的,因为还没有训练的结果。 - 上方左侧的
Train按钮是在中间部分TrainingData选择导入数据后,开始训练。 - Data部分分别可以用刚刚下载的文件夹中的内容,但是首先要导入
Train的文件,并且等训练结果出来后,可以继续后面的步骤。 - Parameters部分
- Algorithm是选择算法,默认的
FullNetworking是基于YOLOv2的,可以选择TransferLearning,TransferLearning与样本数量相关,训练出的模型也更小。至于什么是YOLOv2,可以参考这篇文章A Gentle Introduction to Object Recognition With Deep Learning,看完会对深度学习的几种算法有大致的理解 Iterations训练的迭代次数,并不是越大越好,也不能太小。Batch Size,每次迭代训练的数据大小,值越大占用的内存越大。参考What is batch size in neural network?Grid Size,参考gridsize,YOLO算法中分割图片为多少块。
- Algorithm是选择算法,默认的
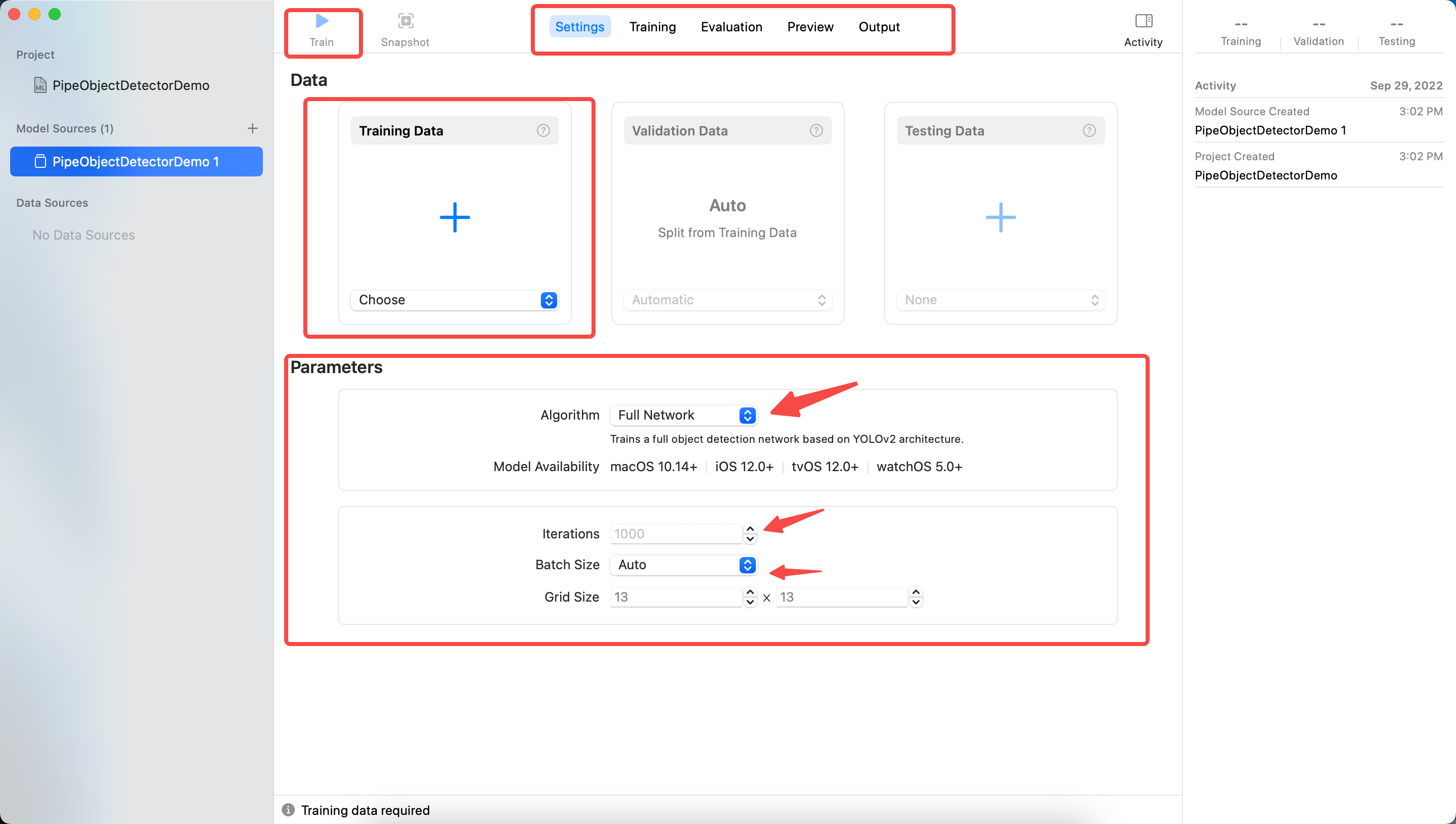
这里设置Iterations为100,其余采用默认设置,然后点击Train,会进入Training的步骤,最终结果如下:
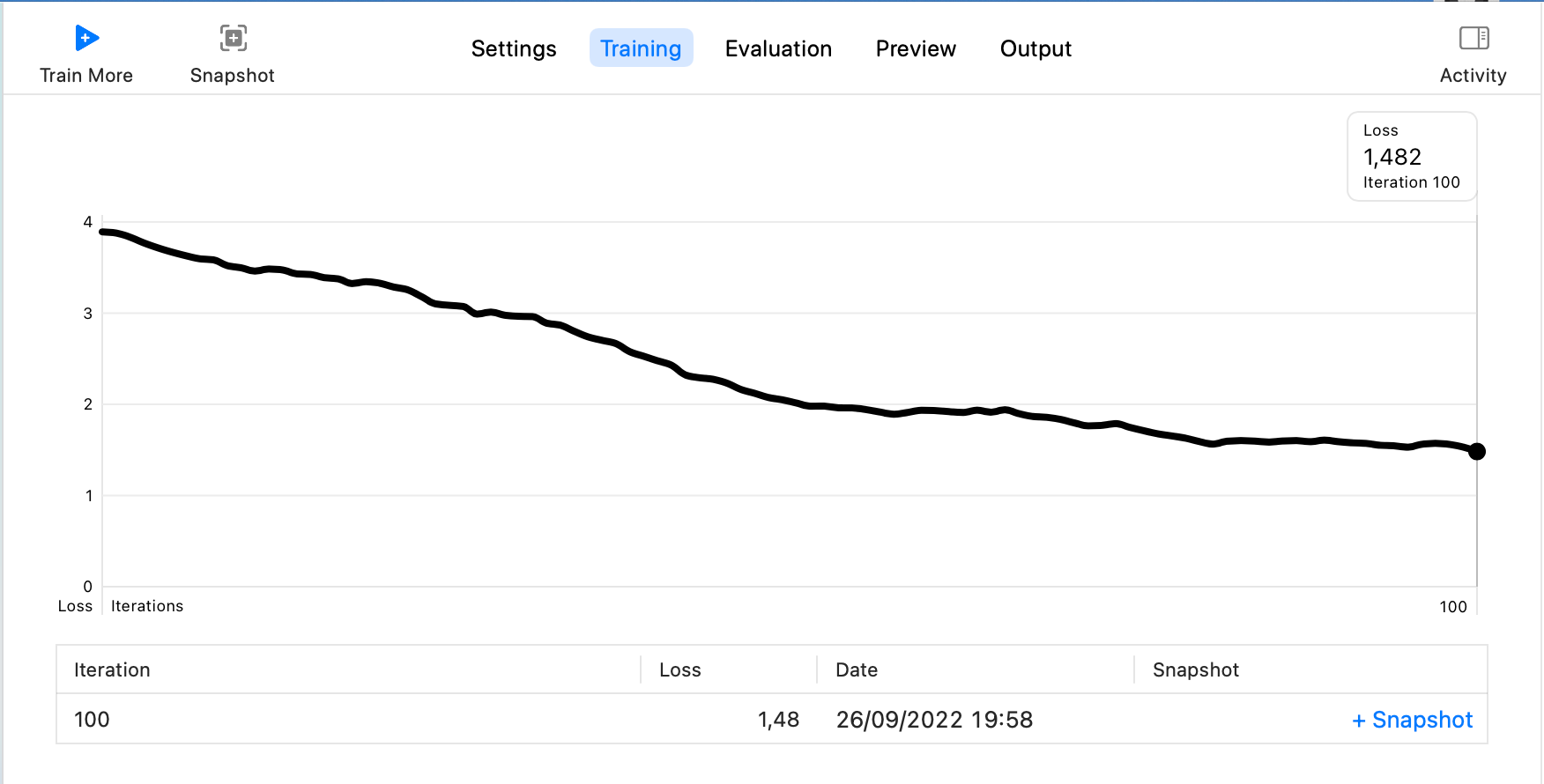
然后选择Testing Data,由于下载的标注中Test只有两条数据,所以可以接着用Train来作为Testing Data的数据,点击Test,然后等待结果出现,如下:
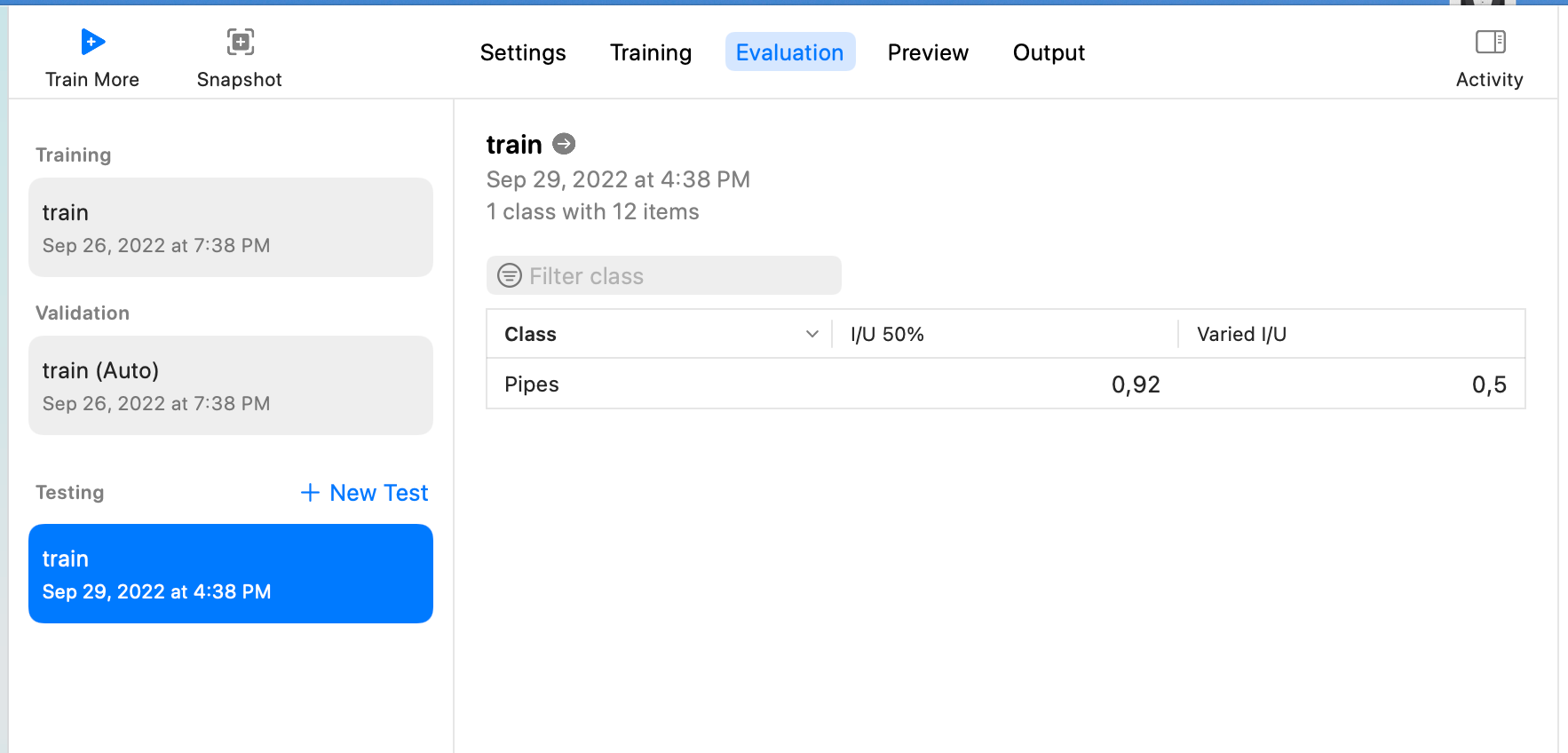
这个页面上的I/U 50%和Varied I/U的意义可参考CreateML object detection evaluation
I/U means “Intersection over Union”. It is a very simple metric which tells you how good the model is at predicting a bounding box of an object. You can read more about I/U in the “Intersection over Union (IoU) for object detection” article at PyImageSearch.
So:
I/U 50% means how many observations have their I/U score over 50%
Varied I/U is an average I/U score for a data set
也可以通过Preview更直观的查看识别效果,如下,点击添加文件,选择所有钢管照片
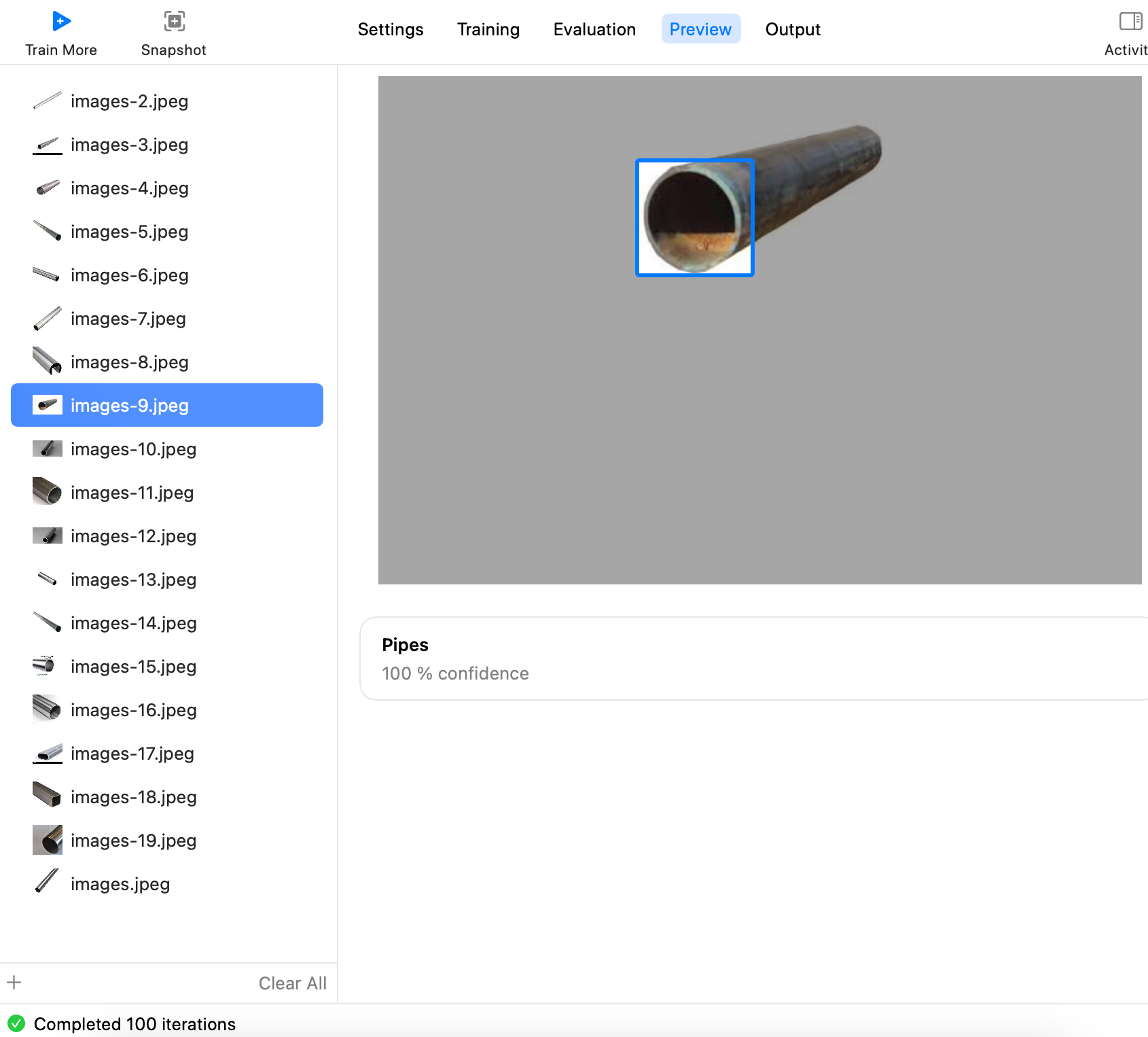
然后一张张查看,就可以看到每张能不能识别出
最后,切到Output,点击Get,导出模型xxx.mlmodel,如下:
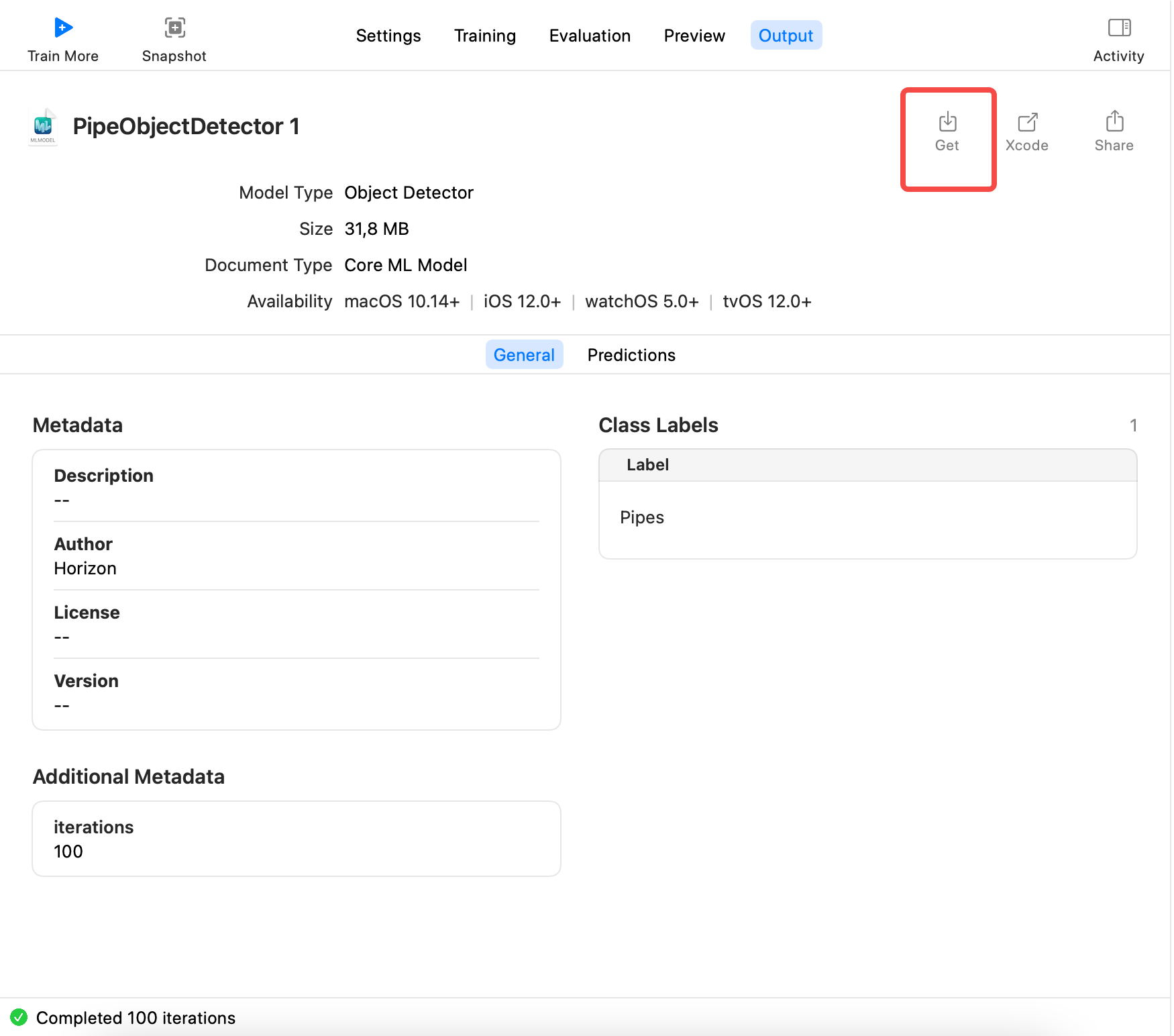
训练出的模型mlmodel的使用
新建一个项目,把训练出的模型导入到项目中,如下:
然后导入Vision库,加载一张照片,然后生成VNImageRequestHandler,用生成的handler去识别,代码如下:
1 |
|
最终效果如下,完整代码已放在Github: CreateMLDemo

总结
本篇介绍了CreateML的整体流程,从模型标注 ,到训练生成模型,再到使用模型,希望大家能对CreateML有大致的了解。后面再来研究下,已导入项目中的模型,能否更新,如何更新?以及尝试做自己的短信过滤APP。
参考
- Create ML
- Creating an Object Detection Machine Learning Model with Create ML
- Object Detection with Create ML: images and dataset
- Object Detection with Create ML: training and demo app
- On-device training with Core ML – part 1
- Core ML Explained: Apple’s Machine Learning Framework
- A Gentle Introduction to Object Recognition With Deep Learning
- Turi Create